In this post, we go through extending a Spark application and also Spark APIs by some examples. These two kinds of extensions are sometimes related, and we go with extending a Spark application first.
Extend a Spark Application
When we write a Spark application, it quite common that our code depends on other projects. There are several
ways to submit your application to Spark with dependencies. The first way is to create an assembly jar (or “uber” jar) containing your code and its dependencies. Both sbt and Maven have assembly plugins.
Another more easy and common way is to use --jars option of spark-submit command to specify your dependent jars and these jars are automatically transferred to the cluster. For Python, the equivalent --py-files option can be used to distribute .egg, .zip and .py libraries to executors.
If you use Maven to manage your dependencies, you can simply supply a comma-delimited list of Maven coordinates with --packages. All transitive dependencies are handled when using this command. Additional repositories (or resolvers in SBT) can be added in a comma-delimited fashion with the flag --repositories. If you want to know more about these methods you can find more information on Spark Document.
Spark also allow specify a default spark.jars and spark.packages in spark-defaults.conf configuration file. These two properties can specify programmatically in your application. What I found out is that if the --jars and --packages options will override corresponding properties in the configuration file and specifying these two properties programmatically sometimes do not work.
Putting the dependencies jars directly into ${SPARK_HOME}/jars directory is another method. This effect all the applications, and if you submit an application with deploy-mode=cluster option, you need to make sure the dependencies jars exits in the Spark lib directory of driver machine.
Examples code for testing these methods can be found here: extend_spark_application_example. If you want to know more about all these options, you can read the discussion here.
Extend Spark APIs
Sometimes we may find that Spark APIs cannot satisfy our requirements. Therefore we want to add some custom feature into Spark APIs.
If we add new APIs, we can simply package our extension code and put the jar file into ${SPARK_HOME}/jars.
Use extension points
If we want to modify Spark APIs, things became a bit more complicated. Spark provides some extension points which added in SPARK-18127 that can be used to inject our custom code. For example, The SparkSessionExtensions provides the following extension points:
- Analyzer Rules.
- Check Analysis Rules
- Optimizer Rules.
- Planning Strategies.
- Customized Parser.
- (External) Catalog listeners.
spark-authorizer, one of the projects I involved, is using SparkSessionExtensions to inject an optimizer rule that used to implement user authorization. I demonstrate the steps below.
Step 1: Create an Optimizer rule class
To implement the authorization, use the AuthorizerExtension class as shown in the following example:
package org.apache.spark.sql.catalyst.optimizer
case class AuthorizerExtension(spark: SparkSession) extends Rule[LogicalPlan] with Authorizable
trait Authorizable extends Rule[LogicalPlan] with Logging {
def spark: SparkSession
override def apply(plan: LogicalPlan): LogicalPlan = {
val operationType: HiveOperationType = getOperationType(plan)
val (in, out) = PrivilegesBuilder.build(plan)
spark.sharedState.externalCatalog match {
case _: HiveExternalCatalog =>
try {
AuthorizationProvider.checkPrivileges(
spark,
new AuthorizationRequest(operationType, in, out)
)
} catch {
case hae: HiveAccessControlException =>
error(
s"""
|+===============================+
||Spark SQL Authorization Failure|
||-------------------------------|
||${hae.getMessage}
||-------------------------------|
||Spark SQL Authorization Failure|
|+===============================+
""".stripMargin)
throw hae
case e: Exception => throw e
}
case _ =>
}
// iff no exception.
// We just return the original plan here, so this rule will be executed only once.
plan
}
Step 2: Create a first-class function with the Extension Points API to add a new rule
package org.apache.spark.sql.authorization
class AuthorizationExtension extends (SparkSessionExtensions => Unit) {
override def apply(ext: SparkSessionExtensions): Unit = {
ext.injectOptimizerRule(AuthorizerExtension)
}
}
Step 3: Enable the customized rule
There are two ways to enable customized rule. One is using the withExtensions option when creating SparkSession.
val spark = SparkSession.builder().withExtensions(AuthorizerExtension).getOrCreate()
However, we want the authorization rule to be enabled by default, so we choose to configure the spark-defaults.conf by adding the following line.
spark.sql.extensions org.apache.spark.sql.authorization.AuthorizationExtension
SparkSessionExtensions do not work on pyspark 2.2.x and 2.3.x. You can find the issue discussed here.
Modify Spark source code directly
Sometimes the extension point many can match our need for some reasons. One of this situation is that there is a bug in Spark that affects our application, and this bug will not be fixed by Spark maintainers. One of these bugs I run into is SPARK-24570: Spark Thrift Server having a problem showing schemas SQL client tools. I solved this problem by modify Spark source code directly and built a new thrift-server jar.
Use aspect-oriented programming (AOP) extension
Because Scala, the native program language used by Spark, is a JVM language. So we can AspectJ to intercept Spark code. In this way, we can modify the Spark APIs without modifying Spark source code directly.
For those not familiar with AspectJ, here is a brief introduction. AspectJ is an aspect-oriented programming (AOP) extension created at PARC for the Java programming language. AspectJ has become a widely used de facto standard for AOP by emphasizing simplicity and usability for end users.
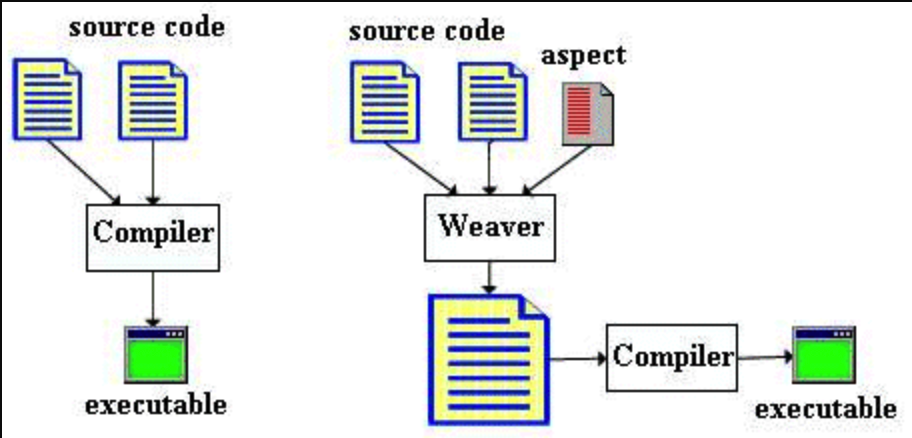
I used AspectJ in the spark-authorizer project. I use it to enhance Spark SessionCatalog, making it only return the databases and tables user have privileges to access.
Step 1: Create a aspect class
package org.apache.spark.sql.catalyst.catalog
...
class SessionCatalogAspect extends Logging {
private lazy val spark: SparkSession = SparkSession.getActiveSession
.getOrElse(SparkSession.getDefaultSession.get)
@Around(
"execution(public * org.apache.spark.sql.catalyst.catalog.SessionCatalog.listDatabases(..))"
)
def filterListDatabasesResult(pjp: ProceedingJoinPoint): Seq[String] = {
logDebug("filterListDatabasesResult")
val dbs = pjp.proceed.asInstanceOf[Seq[String]]
val operationType: HiveOperationType = HiveOperationType.SWITCHDATABASE
val requests = dbs.map { db =>
val inputObjs = new JAList[HPO]
val outputObjs = new JAList[HPO]
inputObjs.add(
HivePrivilegeObject(HivePrivilegeObjectType.DATABASE, db, db))
new AuthorizationRequest(operationType, inputObjs, outputObjs)
}
val result = AuthorizationProvider.checkPrivileges(spark, requests)
(dbs zip result).filter(_._2).map(_._1)
}
...
}
Step 2: create a AspectJ configuration file
create a aop.xml file in META-INFO:
<?xml version="1.0" encoding="UTF-8" ?>
<aspectj>
<aspects>
<aspect name="org.apache.spark.sql.catalyst.catalog.SessionCatalogAspect"/>
</aspects>
<weaver options="-Xset:weaveJavaxPackages=true"/>
<weaver options="-XaddSerialVersionUID"/>
</aspectj>
Step 3: enable AspectJ aspects in Spark
To enable AspectJ aspects in Spark, you need to put the jar file contains the aspects into ${SPARK_HOME}/jars and add the following line to spark-defaults.conf.
spark.driver.extraJavaOptions -javaagent:/path/to/aspectjweaver-{version}.jar
Handle code conflict with Spark Code
Spark itself has large source code and depends on many third party projects. When you add code to extend Spark, there is a risk that your code or the dependencies of your code conflict with Spark code. The maintainers of Spark do try to decrease the possibility of conflict. That’s the reason they replace Akka with alternative RPC implementations and a common event loop in Spark. As a user, we also have some methods to avoid these conflicts.
Shade your code
Shading a dependency consists of taking its content (resources files and Java class files) and renaming some of its packages before putting them in the same JAR file. Both SBT and Maven have shade plugins.
An example for shading use SBT can be found wsargent/shade-with-sbt-assembly: SBT project showing shading a library with SBT assembly
An example for shading use Maven can be found on the Spark Thrift Service source code I modified.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.apache.spark</groupId>
<artifactId>spark-parent_2.11</artifactId>
<version>2.3.2</version>
<relativePath>../../pom.xml</relativePath>
</parent>
<artifactId>shaded-spark-hive-thriftserver_2.11</artifactId>
<packaging>jar</packaging>
<name>Shaded Spark Project Hive Thrift Server</name>
<url>http://spark.apache.org/</url>
<properties>
<sbt.project.name>shaded-hive-thriftserver</sbt.project.name>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive-thriftserver_${scala.binary.version}</artifactId>
<version>${project.version}</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/scala-${scala.binary.version}/classes</outputDirectory>
<testOutputDirectory>target/scala-${scala.binary.version}/test-classes</testOutputDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration >
<artifactSet>
<includes>
<include>org.apache.spark:spark-hive-thriftserver_${scala.binary.version}</include>
</includes>
</artifactSet>
<relocations>
<relocation>
<pattern>org.apache.spark.sql.hive.thriftserver</pattern>
<shadedPattern>shaded.org.apache.spark.sql.hive.thriftserver</shadedPattern>
<includes>
<include>org.apache.spark.sql.hive.thriftserver.**</include>
</includes>
</relocation>
</relocations>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
I created a new module called shaded-spark-hive-thriftserver to shade the code from the original spark-hive-thriftserver module. After this shading, I use the shaded class shaded.org.apache.spark.sql.hive.thriftserver.HiveThriftServer2 as the Main class of my application, so I don’t need to replace the original spark-hive-thriftserver jar in the Spark lib directory.
Shim
By renaming resources, shading avoids possible resource conflicts. It’s powerful but also limited. User needs to use the renamed resources on his own. Think about injecting an authorization rule into Spark mentioned above. The authorization rule has third-party dependencies. To keep the functionality of the authorization rule and avoid possible code conflicts at the same time, we need to make the extension class visible for Spark while other classes are isolated from Spark. The way of doing this is by using a shim.
In computer science, shims can have two meanings. In general, a shim is a small library that transparently intercepts an API, changing the parameters passed, handling the operation itself, or redirecting the operation elsewhere. This kind of shims is used in Spark, like the HiveShim, but what I am going to talk about is the other kind of shims. These shims are used to isolate your application code from other parts of the system. Shims divert calls to specific methods to the actual implementation code that you write.
When I developing the spark-authorizer project, I got this shim idea from ranger-hive-plugin-shim, then I developed a similar shim for the spark-authorizer.
When a class is loaded into two runtime classes by different ClassLoaders, these two classes are treated as different classes in JVM runtime. The principle behinds this kind of shims is that we create a proxy class for our application entrance class, and then this proxy uses an independent ClassLoader to load you actual implement class from a specific place. The proxy redirects the calls to the actual class. Therefore the real code is isolated. Below is the shim code I wrote for AuthorizationExtension.
package org.apache.spark.sql.authorization
class AuthorizationExtension extends (SparkSessionExtensions => Unit) with Logging {
private val SPARK_PLUGIN_TYPE = "authorizer"
private val AUTHORIZER_IMPL_CLASSNAME = "org.apache.spark.sql.catalyst.optimizer.AuthorizerExtension"
private lazy val pluginClassLoader = SparkPluginClassLoader.getInstance(SPARK_PLUGIN_TYPE, this.getClass)
private lazy val authorizerImpl: SparkSession => Rule[LogicalPlan] = {
logDebug("==> AuthorizationExtension.init()")
try {
val cls = Class.forName(AUTHORIZER_IMPL_CLASSNAME + "$", true, pluginClassLoader)
activatePluginClassLoader()
val instance = cls.getField("MODULE$").get(cls).asInstanceOf[SparkSession => Rule[LogicalPlan]]
logDebug("<== AuthorizationExtension.init()")
instance
} catch {
case e: Exception => {
// check what need to be done
logError("Error Enabling AuthorizationExtension", e)
throw e
}
} finally deactivatePluginClassLoader()
}
private def activatePluginClassLoader(): Unit = {
if (pluginClassLoader != null) pluginClassLoader.activate
}
private def deactivatePluginClassLoader(): Unit = {
if (pluginClassLoader != null) pluginClassLoader.deactivate
}
override def apply(ext: SparkSessionExtensions): Unit = {
ext.injectOptimizerRule(authorizerImpl)
}
}