Spark running mode is often be confused with application deploy mode.
Spark Running Mode
Spark can run on a single local machine or on a cluster manager like Mesos or YARN to leverage the resources(memory, CPU, and so on) across the cluster.
Run Locally
In local mode, spark jobs run on a single machine and are executed in parallel using multi-threading: this restricts parallelism to (at most) the number of cores in your machine.
The local mode can be enabled by setting the [master url][master-url] to local or local[x]. The biggest advantage of the local mode is that you don’t need to deploy a Spark cluster before you run a Spark application, so it’s usually used for developing and testing a Spark application.
Run on Cluster
Spark support serval type of cluster managers.
The system currently supports several cluster managers:
- Standalone – a simple cluster manager included with Spark that makes it easy to set up a cluster.
- Apache Mesos – a general cluster manager that can also run Hadoop MapReduce and service applications.
- Hadoop YARN – the resource manager in Hadoop 2.
- Kubernetes – an open-source system for automating deployment, scaling, and management of containerized applications.
A third-party project (not supported by the Spark project) exists to add support for Nomad as a cluster manager.
Examples of submitting an application on different types of cluster can be found on Spark Offical Documents.
Below is an example that uses docker-compose and jupyter/pyspark-notebook docker image to set up a Spark Standalone Cluster and use the cluster for Jupyter.
Spark Application Deployment Mode
Before we going to the detail of deployment mode, we should know about the components of a Spark application.
A Spark application is composed of the driver and executors that can run locally (on a single JVM) or using cluster resources (like CPU, RAM and disk that are managed by a cluster manager).

Deploy modes are all about where the Spark driver runs. Spark provides two types of deploy mode: client and cluster. In client deploy mode, the Spark driver (and SparkContext) runs on a client node outside a cluster whereas in cluster mode it runs inside a cluster, i.e. inside a YARN container alongside ApplicationMaster (that acts as the Spark application in YARN).
Deploy mode can be specified using the --deploy-mode parameter or spark.submit.deployMode when submitting a Spark application.
Note
cluster deploy mode is only available for non-local cluster deployments.
Client Deployment Mode
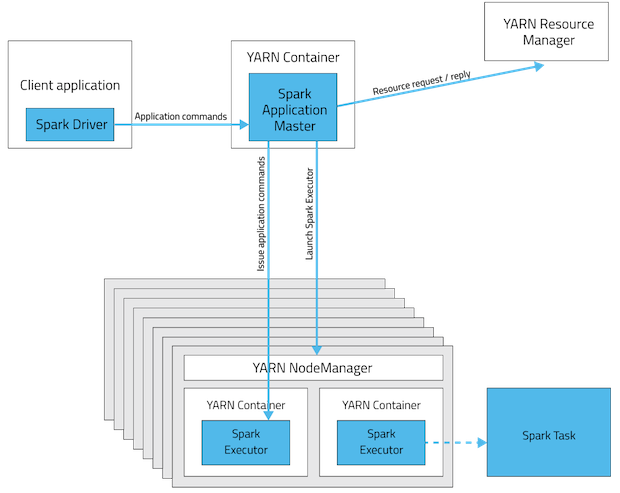
Client deployment mode is the default mode when submitting a Spark application. In client mode, the driver daemon runs in the machine through which you submit the spark job to your cluster. This mode is great when you want to use Spark interactively like give some user input or use any shell command. Also, in this mode, you can use actions like take() or collect() which fetch all transformation results to the driver program and can be seen.
Cluster Deployment Mode
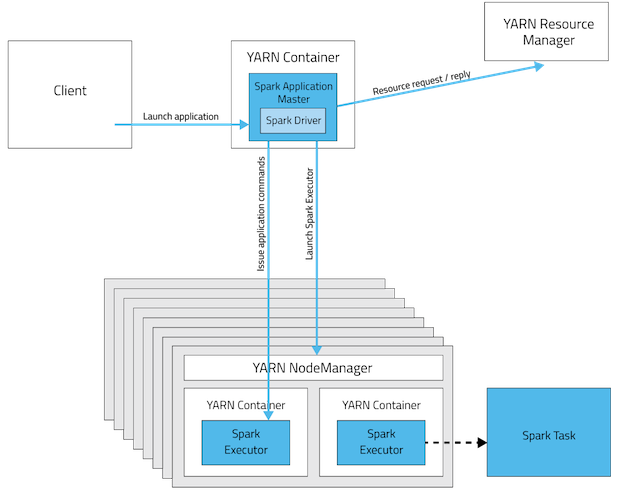
In cluster mode, you don’t get to use the spark job interactively as the client through which you submit the job is gone as soon as it successfully submits the job to cluster. In this mode, most of the time, it’s a waste of memory to use take(), as it will fetch all the results to your driver (in the cluster and not in the client that submit the job). So you may want to store the results of your transformation to a distributed environment like HDFS.
Some resources have to be reserved for the driver daemon process as it will be running in your cluster.
Note
Cluster deploy mode is not applicable to Spark shell tools, including spark-shell, pyspark and spark-sql.
Reference and Further Reading
- Running Spark Applications on YARN | 5.4.x | Cloudera Documentation
- Spark on YARN · The Internals of Apache Spark
- Deploying Spark on Kubernetes Spark Standalone Cluster using Jupyter Docker Image
- Docker-composing Apache Spark on YARN image on waitingforcode.com - articles about Apache Spark
- Deploying Spark on Kubernetes | TestDriven.io