Spark SQL
Spark SQL is a module for working with structured data
spark = SparkSession.builder.config(conf=conf).enableHiveSupport().getOrCreate()
spark.sql("use database_name")
spark.sql("select * from table_name where id in (3085,3086,3087) and dt > '2019-03-10'").toPandas()
Hive
Data warehouse software for reading, writing, and managing large datasets residing in distributed storage and queried using SQL syntax.
Hive transforms SQL queries as Hive MapReduce job.
Besides MapReduce, Hive can use Spark and Tez as execute engine.
Spark and Hive
In Spark 1.0, Spark use many Hive codes in Spark SQL. It ran Hadoop style Map/Reduce jobs on top of the Spark engine
There is almost no Hive left in Spark 2.0. While the Sql Thrift Server is still built on the HiveServer2 code, almost all of the internals are now completely Spark-native, for example Spark it build a brand new Spark-native optimization engine knows as Catalyst.
HiveServer2
A server interface that enables remote clients to execute queries against Hive and retrieve the results.
With HiveServer2, we can use JDBC and ODBC connecters to connect to Hive.
Spark Thrift Server
Spark Thrift Server is variant of HiveServer2.
Thrift is the RPC framework use for client and Server communication.
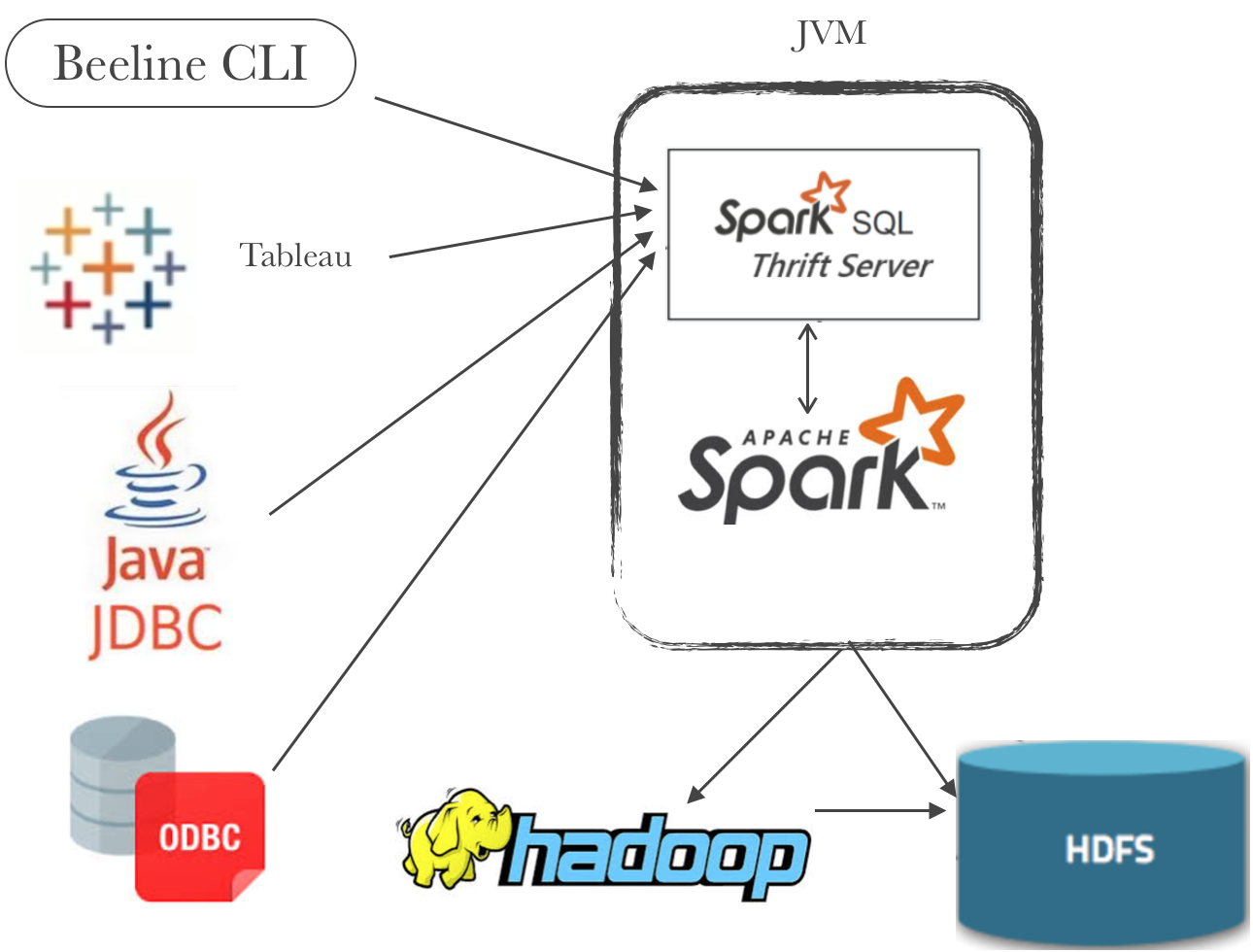
Spark Thrift Server have a bug in showing db schemes and tables. We cherry-picked the patch codes into Spark 2.3.2 the version we now used and used a shaded jar in deploying Spark Thrift Server.
[SPARK-24196] Spark Thrift Server - SQL Client connections does’t show db artefacts - ASF JIRA
“Inception” or “Multiple Sessions”
From Spark 1.6, by default, the Thrift server runs in multi-session mode
spark.sql.hive.thriftServer.singleSession=false
“Mysterious OOMs and How to Avoid Them” or “Incremental Collect”
spark.sql.thriftServer.incrementalCollect=false
The setting IncrementalCollect changes the gather method from collect to toLocalIterator.
Metastore
Central repository of Hive metadata.

Metastore need a warehouse location for storage for internal tables data. Although we only use external tables, the warehouse location is still needed because every database in Metastore needs a corresponding folder in the warehouse. Spark references spark.sql.warehouse.dir as the default Spark SQL Hive Warehouse location. In EMR cluster this property is config to cluster HDFS location by default. If the cluster goes down the HDFS will become unavailable and this may cause some problem in using Spark SQL to query table data. Therefore we the location to the local file system. In other words, config spark.sql.warehouse.dir to file:///usr/lib/spark/warehouse in spark-defaults.conf.
References
Russell Spitzer’s Blog: Spark Thrift Server Basics and a History